
La Conferencia Internacional sobre Computer Vision (ICCV por sus siglas en inglés) es la piedra angular en el campo de investigación y desarrollo de la visión por ordenador. Organizada cada dos años, la ICCV sirve como plataforma vital para la comunidad mundial de científicos, investigadores, ingenieros y profesionales de la Computer Vision con el fin de reunirse, intercambiar conocimientos y mostrar los últimos avances en el sector. Con una rica historia y una perspectiva futurista, el ICCV sigue siendo fundamental para moldear la trayectoria de esta disciplina en rápida evolución, y continúa siendo un catalizador para los avances innovadores en Computer Vision y sus numerosas aplicaciones en nuestro mundo moderno. La edición 2023 del ICCV se celebró en París del 2 al 6 de octubre, y nuestro equipo asistió a las conferencias, talleres y tutoriales que se organizaron para impregnarse de las tendencias actuales y futuras. Si tiene curiosidad por obtener un resumen de ICCV2023, quédese en este artículo, ¡y feliz lectura!
Por una mayor eficiencia y precisión con Vision Transformer (ViT)
En la búsqueda de algoritmos cada vez más eficaces, los Transformadores de Visión se han abierto camino. A diferencia de las redes neuronales convolucionales (CNN, por sus siglas en inglés) tradicionales, que procesan las imágenes de forma cuadriculada mediante capas convolucionales, las ViT se inspiran en los métodos de procesamiento del lenguaje natural (PLN) utilizando la arquitectura Transformers.
En una ViT, una imagen de entrada se divide en fragmentos de tamaño fijo, que luego se aplanan e incrustan linealmente para formar una secuencia de vectores. Estas secuencias son procesadas por una serie de capas de transformadores, que permiten captar las relaciones y dependencias entre las distintas partes de la imagen. El mecanismo de auto-atención de los transformadores permite al modelo ponderar la importancia de cada parche en relación con todos los demás.
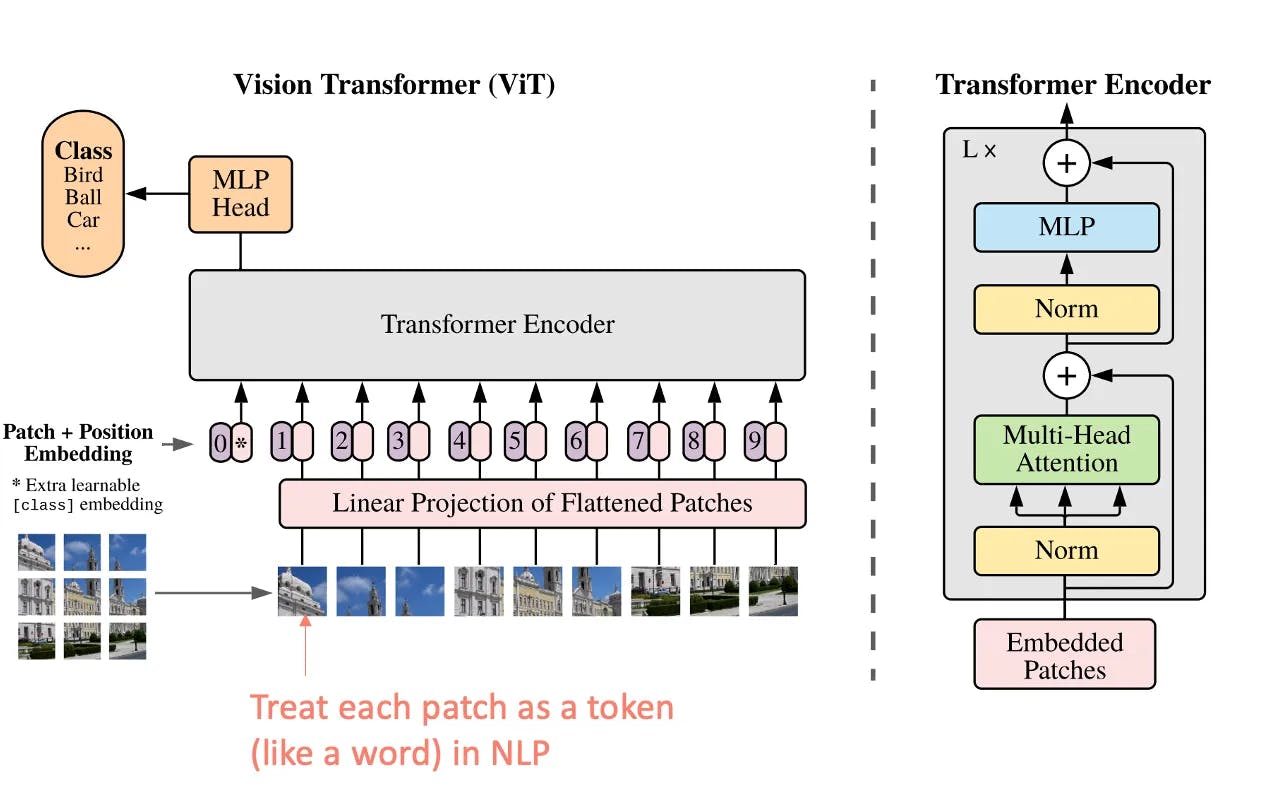
Arquitectura de transformadores modificada para imágenes (ViT) (source)
Las CNN sobresalen en tareas de Computer Vision con grandes conjuntos de datos, mientras que los Transformadores de Visión brillan en situaciones que exigen un contexto global. No obstante, los transformadores de visión necesitan más datos para obtener un rendimiento equivalente al de las CNN, y estas últimas son preferibles para aplicaciones en tiempo real con recursos limitados debido a su eficiencia computacional.
Modelos multimodales: el tema de moda
Los modelos multimodales estuvieron prácticamente en boca de todos en ICCV2023. Pero antes, expliquemos en qué consisten. La mayoría de los modelos actuales de Computer Vision funcionan con datos de una sola modalidad: imágenes, texto o voz. Sin embargo, los datos del mundo real suelen proceder de múltiples modalidades: imágenes con texto o vídeo con audio. Para hacer frente a este reto, los investigadores han desarrollado modelos de aprendizaje automático multimodal que pueden manejar datos de múltiples modalidades, abriendo nuevas posibilidades para los sistemas inteligentes. Curiosamente, la comunidad de Computer Vision no sólo está interesada en fusionar imágenes y texto, o imagen y sonido, sino también otros tipos de modalidades, como la temperatura o la profundidad.
Este enfoque, que ayuda a abordar tareas complejas de Computer Vision, ha permitido avances significativos en varios ámbitos, entre ellos:
- Respuesta a preguntas visuales: se trata de generar respuestas precisas a preguntas sobre una imagen.
- Generación de texto a imagen: consiste en entrenar un modelo para generar imágenes a partir de descripciones textuales.
- Lenguaje natural para el razonamiento visual: el objetivo es evaluar la capacidad de los modelos para comprender y razonar sobre descripciones de escenas visuales en lenguaje natural.
Un ejemplo obvio de modelo multimodal, del que se habló en ICCV2023, es el modelo CLIP (Contrastive Language-Image Pretraining). Este modelo abre nuevas posibilidades, como la capacidad de realizar descripciones complejas del estado de un objeto industrial. En efecto, mientras que los modelos tradicionales de Computer Vision suelen categorizar los objetos en categorías o etiquetas discretas, el modelo CLIP aprende una representación más sutil y contextual de la información visual. Puede captar las sutilezas, las relaciones y la información contextual de una imagen, en lugar de limitarse a reconocer objetos como entidades separadas.
Si trazamos un paralelismo con la principal capacidad de la plataforma de Deepomatic -el análisis de imágenes captadas por técnicos y agentes en campo para controlar automáticamente su trabajo—, podríamos ir más allá de una comprensión booleana de las fotos y, por ende, más allá de un planteamiento de Sí o No al control de calidad.
Nuevas oportunidades en vídeo con visión egocéntrica
Con los avances logrados en la comprensión eficaz y profunda de las imágenes, surgen nuevas oportunidades en el análisis de vídeos. En particular, en algunos de los talleres del ICCV se debatió la aparición del análisis de vídeos egocéntricos, que consiste en comprender los datos visuales desde la perspectiva de una persona que lleva una cámara. Incluye el reconocimiento de acciones, la comprensión de escenas, el seguimiento de la mirada, la percepción de la profundidad, la interpretación contextual, etc. Permite a las máquinas comprender los datos visuales de un modo que se ajusta a la perspectiva natural de los seres humanos.
Analizando vídeos de técnicos trabajando en campo, y no únicamente imágenes antes y después de terminar su trabajo, la computer vision podría obtener valiosos datos sobre el trabajo que se realiza y ofrecer resultados más exhaustivos sobre la calidad de este trabajo.
Modelos fundacionales: ¿el pilar para democratizar la Computer Vision?
Los modelos de base han ido surgiendo con el aprendizaje automático supervisado. Se trata de arquitecturas de redes neuronales previamente entrenadas que sirven de base o punto de partida para una amplia gama de tareas concretas dentro del ámbito de la Computer Vision. Estos modelos se entrenan en conjuntos de datos a gran escala y han aprendido a extraer características significativas de las imágenes. Estos modelos básicos preentrenados ofrecen un relevante punto de partida para muchas tareas de Computer Vision y aprovechan grandes volúmenes de datos. Al perfeccionar estos modelos en conjuntos de datos más pequeños y específicos para tareas como la clasificación de imágenes, la detección de objetos, la segmentación, etc., los investigadores y los profesionales pueden lograr un alto rendimiento con menos datos y recursos informáticos en comparación con el entrenamiento de un modelo desde cero.
Los debates del ICCV2023 mostraron que la promesa de analizar imágenes utilizando vocabulario abierto e incluso lógica básica era innovadora. Sin embargo, las redes en juego son mucho mayores y no hay consenso sobre las estrategias para entrenarlas ni sobre la mejor manera de gestionar los enormes conjuntos de datos asociados. Además, dado que los modelos de base se emplean para construir otros modelos para una amplia gama de aplicaciones, es muy importante establecer un marco regulador, ya que cualquier imprecisión, sesgo o fallo en el nivel de los modelos de base puede repercutir en las aplicaciones posteriores construidas a partir de estos. Este marco debe tener en cuenta el efecto cascada de los errores, la agravación de los sesgos, la necesidad de transparencia y responsabilidad y las consideraciones éticas.
La edición 2023 de la Conferencia Internacional sobre Computer Vision, expuso tendencias revolucionarias. Los modelos multimodales acapararon la atención, revolucionando el procesamiento de datos en diversas modalidades. En particular, CLIP ejemplificó la comprensión visual con matices, yendo más allá del reconocimiento convencional de objetos. El análisis de vídeo egocéntrico presentó nuevas perspectivas y ofreció valiosas ideas para el trabajo de campo. Los Transformadores de Visión (ViT) supusieron un salto en eficiencia y precisión. Los modelos de base juegan un papel crucial en la democratización de la Computer Vision, aunque persisten los retos de escala y las consideraciones éticas. ICCV 2023 reafirma su papel fundamental en la configuración del futuro de la Computer Vision.



